
AI 101: Optimizing LLM Responses (A Summary of OpenAI's Talk)

This is a shorter post summarizing the “A Survey of Techniques for Maximizing LLM Performance” presentation during OpenAI’s first DevDay in November 2023. The talk focuses on strategies around prompt engineering, retrieval-augmented generation, and fine-tuning. Parts of this post are a copy and paste of what was presented during the talk.
Introduction
The talk “A Survey of Techniques for Maximizing LLM Performance” by OpenAI provides a good summary of prompt engineering, retrieval-augmented generation (RAG), and fine-tuning and when to use each technique to optimize large language model (LLM) performance. I highly recommend watching the video for a compressive understanding.
LLMs possess a wealth of knowledge as general models and are the starting points for many projects. Often, these general LLMs require further tailoring to be useful for many applications and this is where techniques such as prompt engineering, RAG, and fine-tuning come in. I’ll touch on each one below.
Approaches
OpenAI provides a good framework for thinking about which of the three paths. But first, an overview of each.

Prompt Engineering
Prompt engineering involves various techniques and styles when writing prompts to improve the quality of the response a LLM generates. Techniques and styles include providing clear, explicit instructions, breaking down complex tasks into multiple steps, and offering a few examples to the LLM during the prompt for in-context learning.
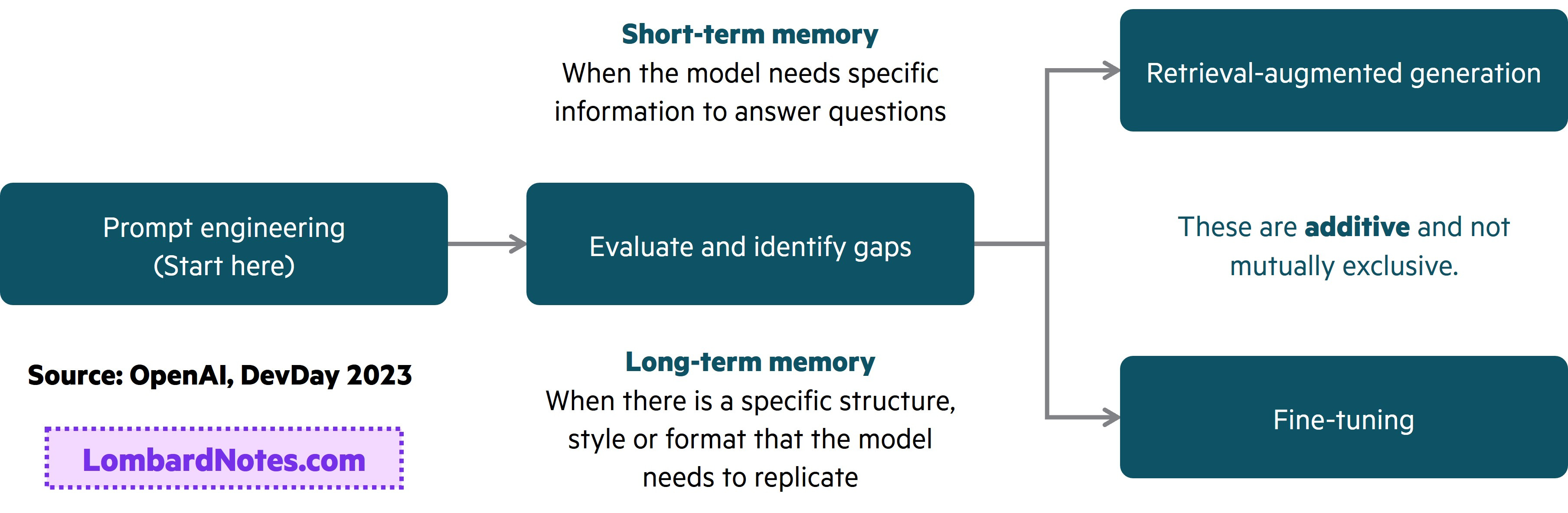
Prompt engineering is typically a great starting point to evaluate and understand gaps in models as well as experimenting different with use-cases, but typically isn’t scalable. From prompt engineering, whether to experiment with RAG, fine-tuning, or both to improve the accuracy of responses from the base model will largely depend on use-cases objectives that need to be achieved.
Retrieval-Augmented Generation
RAG provides LLMs with knowledge and is an effective approach when the model needs specific information to answer questions. RAG works by first searching an existing knowledge base (e.g., a vector database) for relevant content based on the prompt, combining relevant content from the knowledge base with the existing prompt, and sending the combined prompt and content to the LLM for a more relevant answer. One example where RAG may be a good approach is for an internal knowledge Q&A use-case where users can search and interact with a company’s internal policies and procedures. See below for a a general, illustrative diagram.
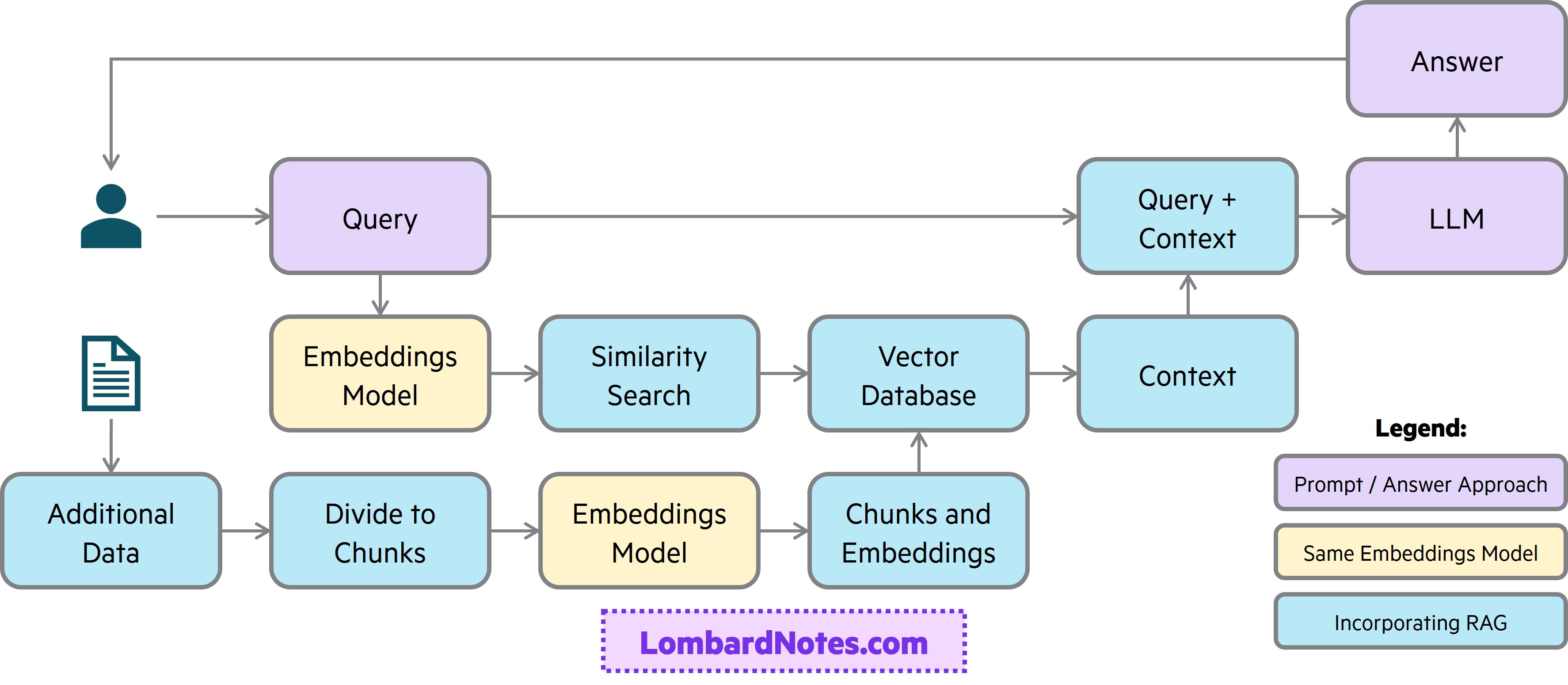
RAG is good for introducing new information to the LLM (although with limitations currently on the breadth of knowledge that can be introduced). RAG is also good for reducing hallucinations by providing the LLM with specific content and instructing the LLM to only use the provided content to answer the question (and not use its existing knowledge).
From the opposite perspective, RAG is not good for incorporating understanding of a broad domain of new knowledge or teaching the model to learn a new language, format, or style. These areas are where fine-tuning or retraining may be better suited - when training new methodologies and frameworks into the LLM will likely yield better responses. In addition, RAG is not a good choice if the goal is to reduce token usage since RAG adds more input and output tokens given additional examples and content combined with each prompt.
Although the basic intuition is simple and more approachable than fine-tuning, implementing RAG can be a highly iterative process and difficult to achieve a desired level of accuracy. There are many different techniques and levers of optimization for implementing RAG such as sentence-window retrieval, auto-merging retrieval, forward-looking active retrieval augmented generation, hypothetical document embedding retrieval, embedding formatting, chain of thought reasoning, fine-tuning the embedding model, and many more (and growing). In addition, some techniques may work well for certain use-cases and not work well for other use-cases, further complicating the process and increasing the time required to discover what combination of techniques works best. However, as the space matures, best practices by use-cases and requirements are likely to emerge and complexities slowly abstracted away with new solutions.
Fine-Tuning
Fine-tuning involves further training an existing general model on a smaller, domain-specific dataset for a specific task. Whereas prompt engineering and RAG are techniques to pack the context window of the LLM during the prompting step, fine-tuning takes a completely different approach by effectively transforming an existing general model into a more specialized model. This is done by adjusting the model’s internal weights and parameters on additional training data. See below for an illustrative diagram.
Fine-tuning improves model performance on specific tasks and is not limited by a LLM’s context window and the amount of data that can be packed in there compared to RAG approaches. At the same time, because it is trained on domain-specific knowledge, fine-tuned models can be more efficient to interact with because they don’t require as many tokens compared to prompt engineering or RAG since they can better reach a desired level of model accuracy without complicated prompts or prompts with additional data. More text in the context window = more input tokens required.
Fine-tuning is good for emphasizing a subset of knowledge that already exists in the model and customizing the structure or tone of responses. One example is fine-tuning a model to respond in a particular JSON structure for better programmatic interactions. Another area where fine-tuning is effective is teaching models very complex instructions. Fine-tuning allows a model to be trained on many more examples than possible though prompt engineering and RAG techniques which are limited by a LLM’s context window.
When is fine-tuning not a good choice? According to OpenAI, fine-tuning is not good for adding new knowledge to a base model. Since the original knowledge of LLMs is embedded into them during extensive pre-training runs, new knowledge is unable to be incorporated during limited fine-tuning runs. Adding new knowledge to LLMs is better done through RAG or if the knowledge is extensive enough, through retraining. Fine-tuning is also not efficient for quickly iterating on new use-cases since fine-tuning requires (sometime substantial) investments in training datasets, compute resources, and other steps involved.
Similar to RAG, the concept of fine-tuning is simple, but implementing fine-tuning can also be a highly iterative process and difficult to achieve a desired level of accuracy. Furthermore, unlike RAG, fine-tuning is also more resource and compute intensive as it requires preparing additional training data and adjusting the weights and parameters of the model. There are also various approaches to fine-tuning, including (1) fine-tuning a subset or adding layer of the LLM parameters through Low-Rank Adaptation (LoRa) or adapter tuning or (2) adjusting all the parameters of the LLM which may be prohibitively costly. Again, similar to RAG, we are in the early days of LLMs and some of the complexities are likely to be abstracted away over time given the number of startups working on solutions to make the fine-tuning process more efficient and approachable.
Summary of Techniques

Fine-Tuning + RAG
Fine-tuning and RAG are not mutually exclusive and can both be implemented to further improve model efficiency. As OpenAI pointed out, fine-tuning can be used to teach a model complex instructions or frameworks. This minimizes prompt tokens needed for complex tasks and maximizes the context window for RAG to incorporate knowledge with the prompt.
Decision Framework for RAG and Fine-Tuning
As mentioned earlier, OpenAI provides a good framework to consider when deciding whether to move from prompt engineering to RAG or fine-tuning after identifying the gaps in the model using prompt engineering. At this point, it may be obvious the decision point is whether the model needs new information for the use-case or specific instructions, structure, and/or style for the use-case or both. For example, when a customer service chatbot needs specific company and product information to be useful, RAG is a good approach. If the same customer service chatbot needs to respond to customers in a specific structure, tone, or style, then fine-tuning is a good approach. Below is effectively the diagram OpenAI provided.
Takeaways
OpenAI’s presentation offers well-structured frameworks and suggestions around prompt engineering, RAG, and fine-tuning. Although these ideas are conceptually easy to grasp, the devil is in the details. Remarkable progress and innovation are happening every day, we are still in the very early stages of Generative AI and figuring out what techniques work best for different use-cases. Enterprises continue to face challenges adopting LLMs, including manual efforts around experimenting, establishing a baseline benchmark, figuring out which methods to use to improve the baseline benchmark, trying different techniques for each use-case, and constantly iterating until (or if) a desired accuracy is reached.
With immense focus and talent working on all things Generative AI, the landscape and techniques may look very different every 6-12 months. In the meantime, there is tremendous opportunity to slowly abstract away some of the complexities into products and services. Once the process of tailoring LLMs becomes more streamlined, we should see an even greater surge in the number of new use-cases and applications emerge. Another potential opportunity in Generative AI is figuring out the best way to combine Generative AI’s probabilistic nature and abilities to create new content, synthesize information, provide answers, and interact with through natural language with traditional deterministic characteristics to meet a broad range of enterprise requirements. Lastly, model choice and flexibility will be critical, particularly early in the technology cycle, when building products given the pace of innovation and fast release cadence of increasingly more performant and/or efficient models.