
AI 101: Vector Databases and Retrieval Augmented Generation (RAG)

This post focuses on vector databases in the context of Generative AI from a non-technical perspective.
Introduction
As with all things related to Generative AI, the popularity of vector databases has grown significantly for good reasons. One of the most basic requirements for enterprises to adopt large language models (LLMs) is the ability to augment LLMs with their proprietary data and customize LLMs for their needs. LLMs such as OpenAI’s GPT-4 or Meta’s Llama 2 are trained on large amounts of data (e.g., publicly available data on the internet), but despite this corpus of knowledge, these models are trained up to a certain date and often require additional data and context to be useful in many applications. Because Generative AI models are effectively very sophisticated prediction systems, when they are asked something they weren’t previously trained on, they will sometimes make up an answer (i.e., their best prediction), widely referred to as hallucinations.
One of the primary techniques to augment LLMs with specific data and context and address hallucinations is retrieval augmented generation (i.e., RAG) and one of the critical components in a RAG architecture is a vector database. With RAG, when a query is made to a LLM, the query is first combined with additional relevant data and context before being sent to the LLM. With additional context and data, the LLM is then able to generate more relevant and precise responses back (more on this later).
Vector Databases Overview
Vector databases have become core components in the world of Generative AI for building LLM applications. It is important to point out there are many use-cases for vector databases other than LLMs including computer vision (e.g., video and image recognition), recommendation systems, and natural language processing (NLP) tasks such as semantic search, enterprise search, sentiment analysis, etc.
Fundamentally, vector databases are purpose-built to efficiently store, retrieve, and search vector embeddings which are mathematical representations of features or attributes that describe and provide contexts and relationships among various data types such as words, sentences, images, videos, etc. Think of a vector embedding as a long list of floating-point numbers (e.g., one of OpenAI’s model produces ~1,500 numbers / dimensions) where each number (1) is a representation of some feature or characteristic of the data determined by an embedding model and (2) relates to numbers from other embeddings (i.e., the proximity of different numbers represents their level of similarly). Put another way, embeddings are a computer’s way to numerically represent the meaning and context of data and how data relate to one another.
Now how do we come up with vector embeddings? As alluded to earlier, there is no shortage of embedding models by data type to choose from used to generate vector embeddings. Some popular models include Google’s open-source models ‘text2vec’ and ‘BERT’ and OpenAI’s proprietary ‘text-embedding-ada-002’. Once the embeddings are generated, they are stored in vector databases and/or used in LLM applications.
Retrieval Augmented Generation
Vector databases enable RAG which have become one of the primary ways to provide additional data and context to LLMs without further training the model. One high-level way to think about RAG is as two parallel processes: (1) pre-processing external data and context and (2) querying the LLM for a response. Below is a diagram as well as high-level steps. The takeaway here is there are many approaches and nuances in implementing RAG with many companies working on what they think the best approaches for information retrieval are.
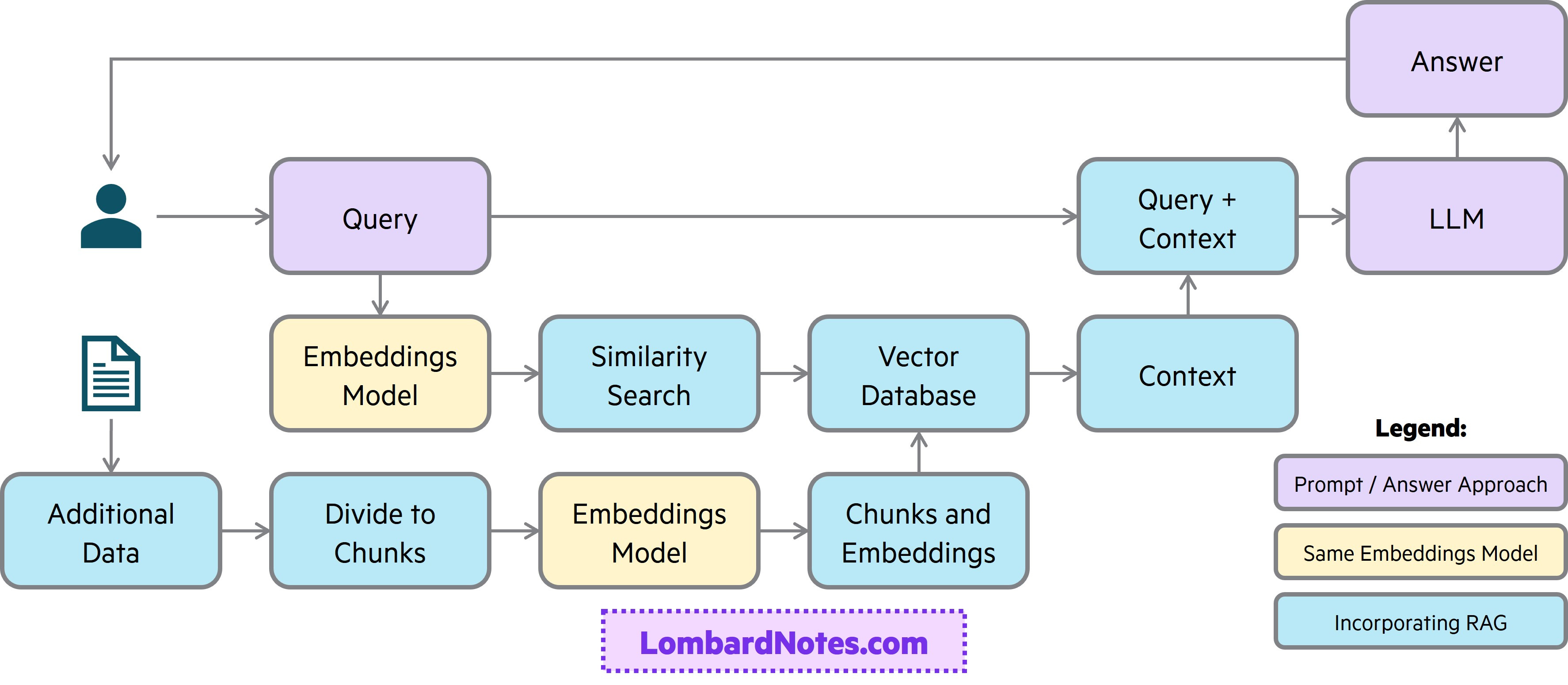
Preprocessing:
Gather data
Divide the data into smaller pieces known as “chunking” (there are many different strategies to chunking depending on the data and context window of the model)
Run the chunks of data through an embedding model (there are many different models to choose from based on types of data and sophistication)
Store the chunks and embeddings in a vector database to be indexed (there are many vector databases to choose from)
Querying:
Input prompt
Run the prompt through the same embedding model used in pre-processing data
With the embeddings of the prompt, run a similarity search for the semantic representation of the prompt to find the most relevant data from the vector database
Query the LLM with the combined prompt and most relevant data
Receive a more relevant response from the LLM
Wait, but what about fine-tuning?
A related and complementary approach to RAG is fine-tuning which involves “adjusting the weights and parameters of a pre-trained model on new data to improve its performance on a specific task” (summarized well by Datacamp). For those that want to add knowledge and data to existing LLMs, RAG is currently the preferred and more approachable method given fine-tuning can be more complex and compute intensive. However, for those that want to further refine a general LLM for specific use-cases and tasks, then fine-tuning may be the preferred approach. There are many “RAG vs. Fine-Tuning” articles out there, but I see these two approaches as complementary rather than one is overall better than the other - which approach or combination will depend on both the goal and constraints of the project.
Vector Database Landscape
Similar to there being no shortage of models to choose from, there is also no shortage of vector capable solutions in the market, whether they are pure-play solutions such as Pinecone and Weaviate or vector-capable solutions such as Elastic and MongoDB. Within pure-play providers, the majority of solutions are open-source with Pinecone standing out as one of the few proprietary options. A quick glance through the documentations of LangChain and LlamaIndex show many options and the lists continue to grow.

Startups have capitalized on the surge of investor interest with Pinecone announcing its $100M Series B at a $750M post in April 2023 while Weaviate announcing its $50M Series B at a $200M post the same month. Existing database solution providers are also fully aware of the trend and have introduced vector capabilities into their platforms as well to cater to the interest of the market.
Takeaways
In the age of Generative AI, vector databases are getting their time in the spotlight. Investors who want exposure to this space have two approaches: (1) Invest in pure-play solutions and hope they become the next MongoDB or get acquired by platforms such as Databricks or Snowflake; and/or (2) Invest in existing data platforms and hope these platforms capture meaningful AI and vector workloads. The success of companies will be determined by a combination of their execution ability, mind share, developer adoption, enterprise features (e.g., governance and privacy), third-party integrations, balance between performance and cost as well as ease-of-use and product customization and sophistication, etc.
Although we are in the very early days of solutions and tooling for Generative AI, the part that is clear is the ability to efficiently store and quickly search vector embeddings are currently critical to LLM applications. The part that will unveil itself over time is which tools and approaches will translate to durable revenue for companies - whether pure-play providers will eventually grow to standalone platforms or vector index and search capabilities will simply be features of existing data platforms or both.
Suggestions, corrections, and feedback for improvement are much appreciated.
Sources and References
https://openai.com/research/gpt-4
https://www.elastic.co/what-is/vector-embedding#/what-is/vector-embedding
https://www.pinecone.io/learn/chunking-strategies/
https://techcommunity.microsoft.com/t5/fasttrack-for-azure/grounding-llms/ba-p/3843857
https://www.datacamp.com/tutorial/fine-tuning-llama-2
https://txt.cohere.com/text-embeddings/
https://python.langchain.com/docs/integrations/vectorstores
https://gpt-index.readthedocs.io/en/latest/community/integrations/vector_stores.html